dev/2: no tests, no failures
Recently, while writing some code for the implementation of my slotted page design for the storage engine, some refactoring was required for the interface that I had originally designed for the page buffer manager. While doing some ad-hoc testing with a simple refactored test case, it became glaringly obvious that my test cases sucked. While running the refactored test case, I ran into a deadlock. The worst part? The code causing the deadlock wasn’t even any of the new or refactored code I was touching: it was old code I had written for the disk scheduler! This meant I had a bug in my code the entire time that wasn’t picked up during any of my testing.
The solution: improve my CI/CD pipeline.
While I did have GTests being built and run on all commits to my remote repository using GitHub Actions, I was still in the dark on what was being tested. Clearly, I was getting some false positives in my test cases, and my testing could be improved.
Code Coverage with gcovr
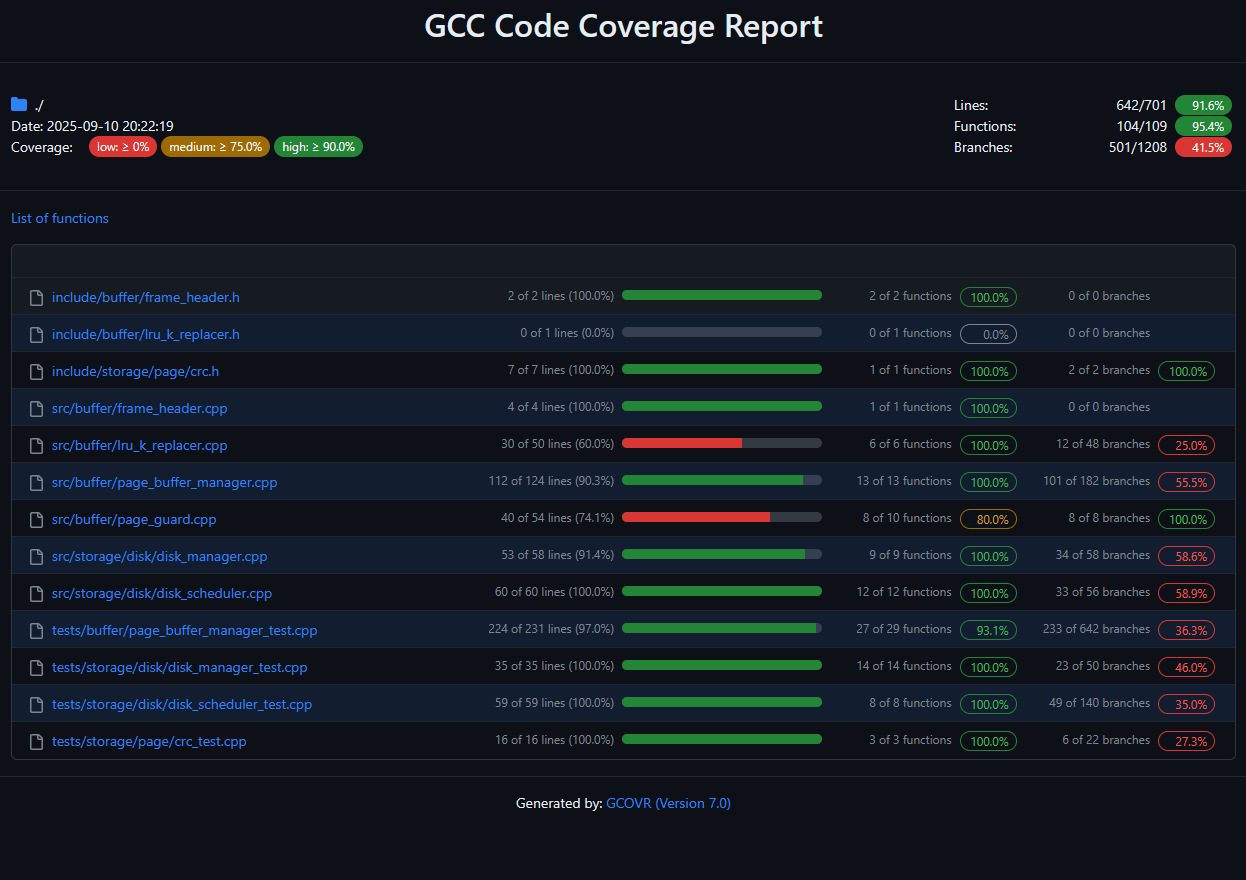
My first idea for an improvement to my testing pipeline was to get some code coverage statistics to see what code paths I was actually hitting and where additional testing might be needed.
Since I was already using g++ as the main compiler for the project, it made
sense to look into a tool like
gcov to get code coverage
reports. Looking around, I quickly found gcovr,
which seemed to be exactly what I was looking for to generate reports in an
easily readable .html format.
After almost having a breakdown fighting with CMake to find a simple way of
adding the required --coverage flag while compiling my library source code1,
I added the necessary steps to run gcovr after running my tests to create
a nice little report that I upload as a test artifact.
What the helgrind?
After integrating gcovr, I was shocked to find that most of my implementations had high code coverage. In fact, most code had >90% coverage. Even though code coverage should never be the only metric of how well your code is tested, I still found it surprising that I had bugs not being picked up.
Since a large portion of the project involves concurrency, I figured it might be useful to use a tool to help detect concurrency bugs.
For this reason, I decided to integrate helgrind, a tool included in valgrind specifically for identifying threading issues like deadlocks or data races.
When I initially ran helgrind with the test cases, it was very clear that there were issues in how I was writing my concurrent code. I haven’t fully integrated helgrind yet, so I might further edit this post in the future to discuss how I work with helgrind’s reports to improve concurrency safety.
TDD Disciple
After this whole ordeal, I had a revelation: code coverage and other tools are great but if my test cases suck, it doesn’t really matter.
Throughout most of the design process, I roughly approximated the interfaces of my components and then dove straight into implementation. Only after completing the implementation did I start writing tests. This rush into implementation almost certainly led to bad tests. Testing was essentially an afterthought.
Which brings me to TDD (Test-Driven Development).
After working in tech for a while — or just browsing Hacker News2 — I occasionally saw the term TDD pop up. I won’t get into what TDD exactly is3, but some of my early exposure was to a kind of fake TDD: developers writing all their test cases first and then implementing everything afterward.
This is not TDD.
Real TDD focuses on incrementally adding a test that would fail, then writing just enough implementation to make it pass — all with the goal of shortening the feedback loop and encouraging more correct, thoughtful code.
Going forward, a TDD approach is something I plan to try in this project to see if there’s real merit to the approach — and, hopefully, improve the quality of both my tests and the code they support.
-
Right now, the main CMake library that contains all of my core logic is an aggregation of existing static libraries. As far as I could tell, using an interface library to logically group all the static libraries together was the proper approach. However, when trying to add compile flags to all the code inside the larger collection, adding compile flags is only allowed at the
INTERFACEscope — meaning only code that links against my main library will use those compile options, not the library itself. I eventually caved and just wrote a not-so-pretty function to add compile options to each static library individually. It works, but I’m not entirely happy with it. ↩ -
I found a really interesting article by the developers of the game Factorio (play it if you haven’t!) about their adoption of TDD, which I first saw on Hacker News. ↩